看了就被混淆的混淆矩陣及相關效能衡量指標
本文介紹機器學習分類模型中的效能衡量指標,重點講解了混淆矩陣(Confusion Matrix),及其相關的各種效能衡量指標,在 這篇 文章中提到模型評估時,機器學習中分類模型的效能衡量指標是以預測值和實際值的正確程度來作為評估。常見的分類模型效能衡量指標包括預測準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F1 Score 或 AUC。
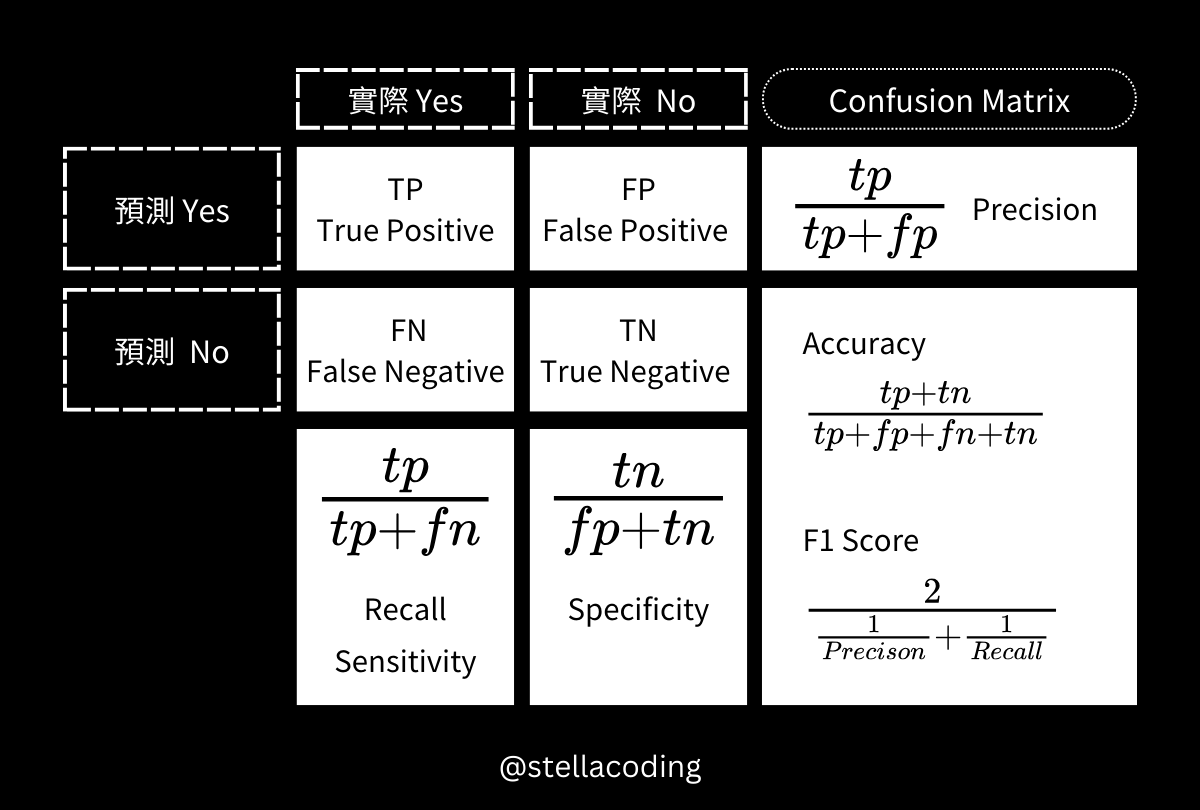
混淆矩陣
混淆矩陣(Confusion Matrix)也稱為誤差矩陣,是可視化演算法性能的視覺化工具。
- 通常用是監督學習演算法,特別是統計分類問題中。
- 在無監督學習中,它通常被稱為匹配矩陣。
| Confusion Matrix | Actual Positive | Actual Negative |
|---|---|---|
| Predicted Positive | TP True Positive |
FP False Positive |
| Predicted Negative | FN False Negative |
TN True Negative |
混淆矩陣可以用字母記憶:
- 開頭是預測正確或錯誤。
- 開頭是T,表示預測與實際一致,即預測正確。
- 開頭是F,表示預測與實際不一致,即預測錯誤。
- 第二個字母是預測結果。
- 第二個字母是P,表示預測是Yes。
- 第二個字母是N,表示預測是No。
所以這4種各代表的意思是:
- TP: True Positive,預測正確,預測是Yes -> 則實際是Yes。
- TN: True Negative,預測正確,預測是No -> 則實際是No。
- FP: False Positive,預測錯誤,預測是Yes -> 則實際是No。
- FN: False Negative,預測錯誤,預測是No -> 則實際是Yes。
| 混淆矩陣 | 實際 Yes | 實際 No |
|---|---|---|
| 預測 Yes | TP: 預測Yes,實際Yes 預測陽性,實際陽性 有病的人,並被判有病 |
FP: 預測Yes,實際No 預測陽性,實際陰性 沒病的人,但被判有病 |
| 預測 No | FN: 預測No,實際Yes 預測陰性,實際陽性 有病的人,但被判沒病 |
TN: 預測No,實際No 預測陰性,實際陰性 沒病的人,並被判沒病 |
雖然你可能已經被混淆,但不要放棄未來成為資料科學家光明的錢途。我們可以用 sklearn.metrics 中的 confusion_matrix 來計算混淆矩陣。(至少不用自己寫混淆矩陣的程式XD)
1 | from sklearn.metrics import confusion_matrix |
1 | True Positive: 3 |
理解完混淆矩陣後,接著來看混淆矩陣延伸出的各種效能衡量指標。
準確率
準確率(Accuracy)是指正確預測的樣本數佔總預測樣本數的比值。
$$ \text{Accuracy} = \frac{tp + tn}{tp + fp + fn + tn} $$
1 | from sklearn.metrics import accuracy_score |
1 | Accuracy: 0.70 |
精確率
精確率(Precision)是指正確預測的正樣本數佔所有預測爲正樣本的數量的比值。
$$ \text{Precision} = \frac{tp}{tp + fp} $$
- 高精確率: 模型預測為正樣本中,大部分是實際為正的。表示誤報(False Positive)較少。
- 低精確率: 模型預測為正樣本中,有很多是實際為負的。表示誤報(False Positive)較多。
1 | from sklearn.metrics import precision_score |
1 | Precision: 0.60 |
召回率
召回率(Recall)是正確預測的正樣本數佔真實正樣本總數的比值。也可稱敏感度(Sensitivity)。
$$ \text{Recall} = \frac{tp}{tp + fn} $$
- 高召回率: 實際為正樣本中,大部分都被模型正確預測為正。表示漏報(False Negative)較少。
- 低召回率: 實際為正樣本中,很多沒有被模型正確預測為正。表示漏報(False Negative)較多。
在解讀 Precision 和 Recall 時,需要根據需求選擇合適指標,才能更好地優化模型性能。
- 如果錯誤預測的成本很高,則應該更注重 Precision。
- 如果漏報的成本很高,則應該更注重 Recall。
1 | from sklearn.metrics import recall_score |
1 | Recall: 0.75 |
F1 Score
在一些應用場景中,我們需要權衡精確率和召回率,因此會使用到 F1 Score。
- F1 Score 是精確率和召回率的調和平均數,常用於綜合評估模型的性能。
- F1 Score 介於 0 和 1 之間,值越大表示模型的整體性能越好。
$$ \text{F1 Score} = \frac{2}{ \frac{1}{Precison} + \frac{1}{Recall} } $$
1 | from sklearn.metrics import f1_score |
1 | F1 Score: 0.67 |
特異度
特異度(Specificity)是指正確預測的負樣本數佔實際負樣本總數的比率。
$$ \text{Specificity} = \frac{tn}{fp + tn} $$
1 | # 計算特異度 |
1 | Specificity: 0.67 |
AUC
AUC(Area Under Curve) 是指 ROC(Receiver Operator Characteristic Curve) 曲線下的面積。
- ROC 曲線以 False Positive Rate (FPR) 為 X 軸,以 True Positive Rate (TPR) 為 Y 軸。
- AUC 值介於 0 和 1 之間,值越大表示模型的正確率越高。
- AUC = 1,代表分類器非常完美。
- AUC > 0.5,代表分類器分類效果優於隨機猜測,模型有預測價值。
- AUC = 0.5,代表分類器分類效果與隨機猜測相同,模型無預測價值。
- AUC < 0.5,代表分類器分類效果比隨機猜測差。
1 | from sklearn.metrics import roc_curve, auc |
1 | AUC Score: 0.71 |