用 H2O AutoML 建立購買機率預測模型
本篇文章介紹如何利用 H2O AutoML 建立一個「潛在用戶購買可能性」的預測模型,藉由預測結果來制定精準的行銷跟進策略。透過此專案,可以將行銷資源聚焦於高潛力用戶,進而提升整體行銷效益。
載入函式庫
安裝套件,並載入函式庫。
1 | pip install pandas sqlalchemy h2o numpy |
1 | import pandas as pd |
準備資料庫
將 CSV 檔案中的潛在用戶與交易記錄資料存入 SQLite 資料庫。
1 | # 讀取CSV檔 |
連線資料庫
1 | sql_engine = sql.create_engine('sqlite:////content/drive/MyDrive/ML/database/leads_transactions.db') |
資料前處理
刪除欄位
刪除不需要欄位。
1 | df = leads_df.drop(columns=['mailchimp_id', 'made_purchase', 'user_full_name']) |
新增欄位
新增預測目標欄位。
1 | target_emails = transactions_df['user_email'].unique() |
模型訓練
1 | h2o.init() |
資料轉換
將資料轉為H2O格式。
1 | hf = h2o.H2OFrame(df) |
設定特徵及目標。
1 | predictors = ['member_rating', 'optin_time', 'country_code', 'optin_days', 'email_provider'] |
建立模型
設定訓練模型上限 20 個,並限定訓練時間 10 分鐘:
max_models=20: 訓練模型數量最多為20個。max_runtime_secs=600: 設定訓練10分鐘。
1 | automl = H2OAutoML(max_models=20, seed=1, max_runtime_secs=600) |
查看模型訓練結果。
1 | lb = automl.leaderboard |
在本次 AutoML 訓練中,最佳模型為 XGBoost_1_AutoML_1_20250224_55852。
其主要評估指標如下:
| model_id | auc | logloss | aucpr | mean_per_class_error | rmse | mse |
|---|---|---|---|---|---|---|
| XGBoost_1_AutoML_1_20250224_55852 | 0.769309 | 0.168819 | 0.203925 | 0.360477 | 0.20612 | 0.0424854 |
儲存模型
1 | h2o.save_model(automl.leader, path="/content/drive/MyDrive/ML/model", filename='best_model_h2o', force=True) |
模型資訊
1 | best_model_h2o = h2o.load_model("/content/drive/MyDrive/ML/model/best_model_h2o") |
混淆矩陣
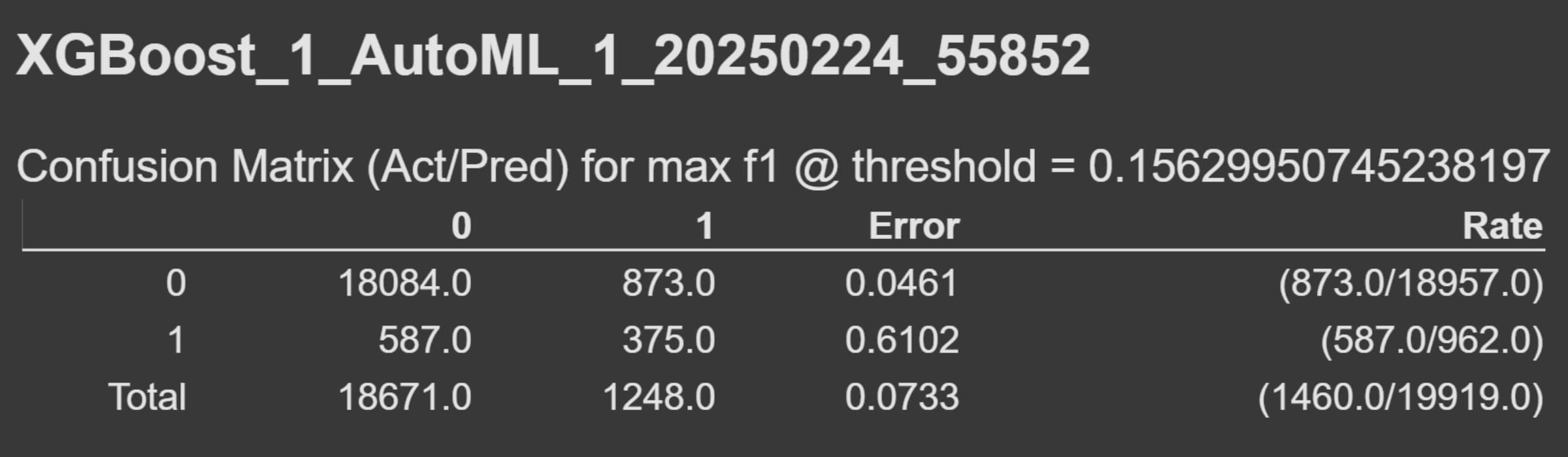
1 | Confusion Matrix (Act/Pred) for max f1 @ threshold = 0.15629950745238197 |
| 實際/預測 | 預測=0 | 預測=1 | 錯誤率 |
|---|---|---|---|
| 實際=0 | 18084 | 873 | 0.0461 |
| 實際=1 | 587 | 375 | 0.6102 |
| 總計 | 18671 | 1248 | 0.0733 |
混淆矩陣展示模型在二元分類問題上的性能指標上的預測與實際之間的對比。
0表示不會購買、1表示會購買。- 總預測為
0: 18671 - 總預測為
1: 1248 - 總錯誤數: 1460,總錯誤率約 7.33%,即總體準確率約 92.67%。
進一步分析錯誤率:
- 假陽性(False Positive, FP)
- 預測為
1,實際為0,總數為873。 - 模型預測「會購買」,但實際上該用戶「沒有購買」。
- –>我們投入的行銷成本就白白浪費。
- 預測為
- 假陰性(False Negative, FN)
- 預測為
0,實際為1,總數為587。 - 模型預測「不會購買」,但實際上該用戶「有購買」。
- –>我們漏判了一群可能帶來營收的用戶。
- 預測為
再進一步計算核心指標:
$$ \text{精確率} = \frac{TP}{TP + FP} = 375 / (375+873) = 0.30 $$
$$ \text{召回率} = \frac{TP}{TP + FN} = 375 / (375+587) = 0.39 $$
針對不同業務目標採取不同的閾值調整方式:
| 業務目標 | 閾值調整 | FN | FP | 精確率變化 | 召回率變化 |
|---|---|---|---|---|---|
| 最大化營收 減少漏掉會購買的用戶(FN↓) |
降低閾值 | FN↓ | FP↑ | 精確率↓ | 召回率↑ |
| 最小化成本 減少無效行銷成本(FP↓) |
提高閾值 | FN↑ | FP↓ | 精確率↑ | 召回率↓ |
特徵重要性
特徵重要性表示在目前這個最佳模型中,各個特徵對預測結果(購買機率)的影響程度。
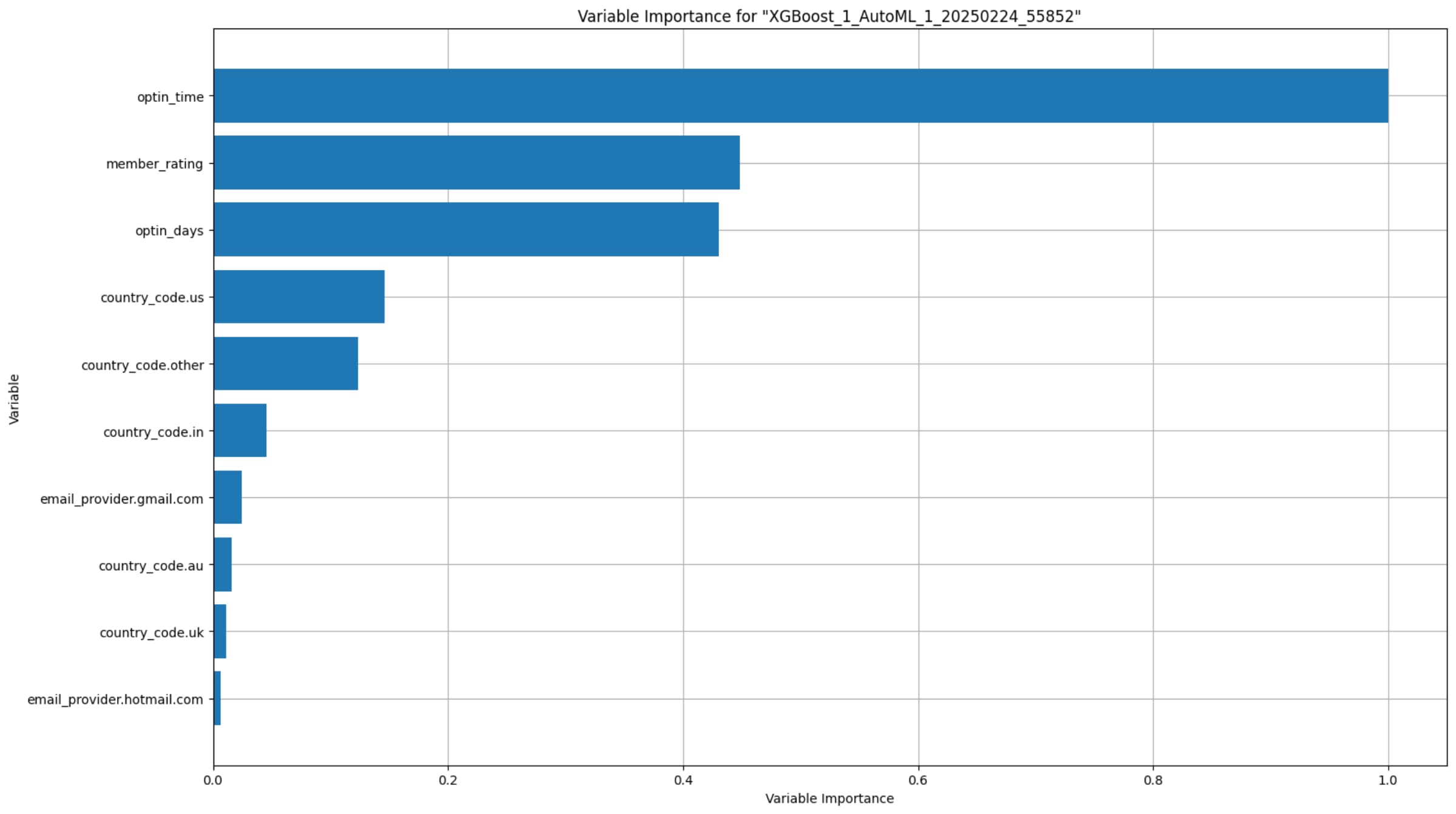
optin_time重要度最高,代表該用戶的「用戶註冊或訂閱時間」對預測是否購買影響最大。member_rating第二,表示用戶活躍度或訂閱分數越高,越可能影響最終是否購買。
SHAP Summary
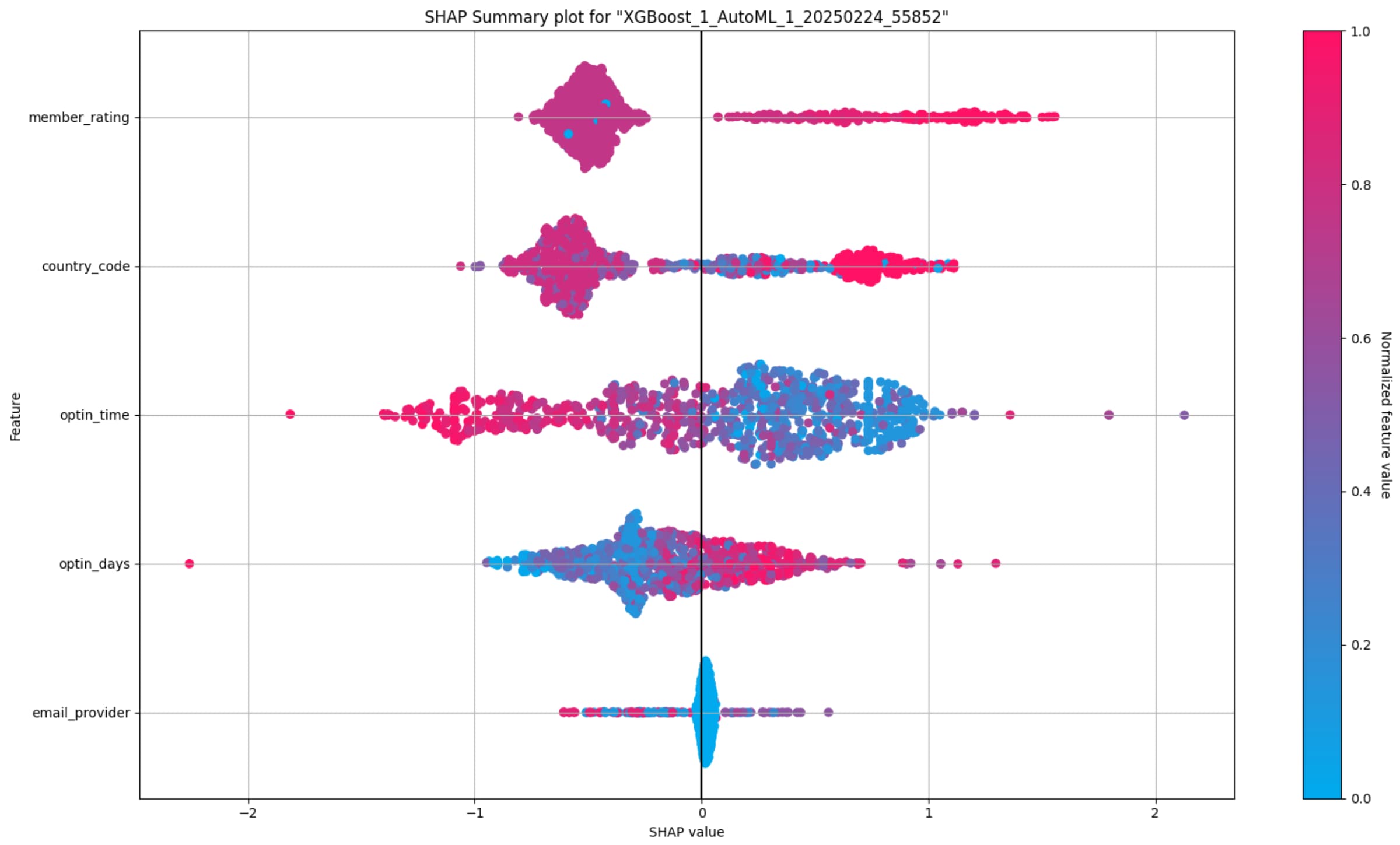
SHAP Summary 顯示每個特徵對預測的貢獻,每一筆資料都會對應到一個 SHAP 值。
- X 軸: SHAP 值。
- 正值表示讓預測值往「購買」方向提升。
- 負值表示讓預測值往「不購買」方向降低。
- Y 軸: 排列出最重要到相對次要的特徵。
- 顏色: 特徵值的大小,越接近紅色代表值越高,越接近藍色代表值越低。
透過 SHAP Summary,我們可以觀察到:
member_rating在最上方,表示該特徵在此模型中的整體影響力較大。- 若紅色點(高評分)集中在右側(正值區),表示「高評分會員」更可能被預測為購買。
- 若藍色點(低評分)集中在左側(負值區),表示「低評分會員」更可能被預測為不購買。
email_provider在最下方,表示該特徵在此模型中的整體影響力相對較小。
部分依賴圖(PDP)
部分依賴圖顯示「在固定其他特徵不變」的情況下,單一特徵與預測結果(購買機率)之間的關係。
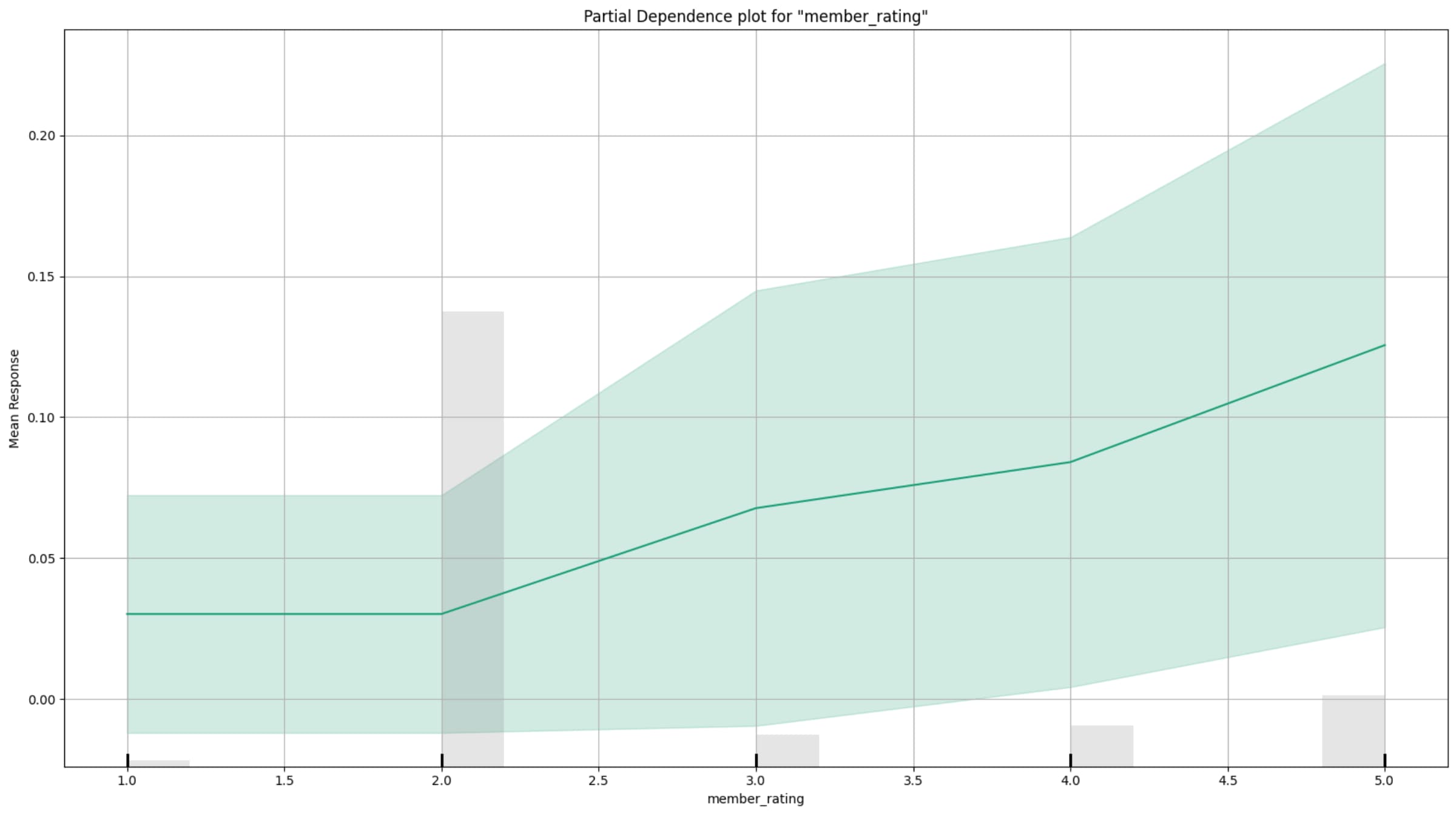
從上圖可以看到,member_rating 越高,模型預測的購買機率也越高,顯示該特徵對「會購買」具有正向影響。換句話說,在其他特徵固定的情況下,會員評等從 1 提升到 5,對應的平均購買機率呈現明顯上升趨勢,代表 member_rating 是個正向特徵。
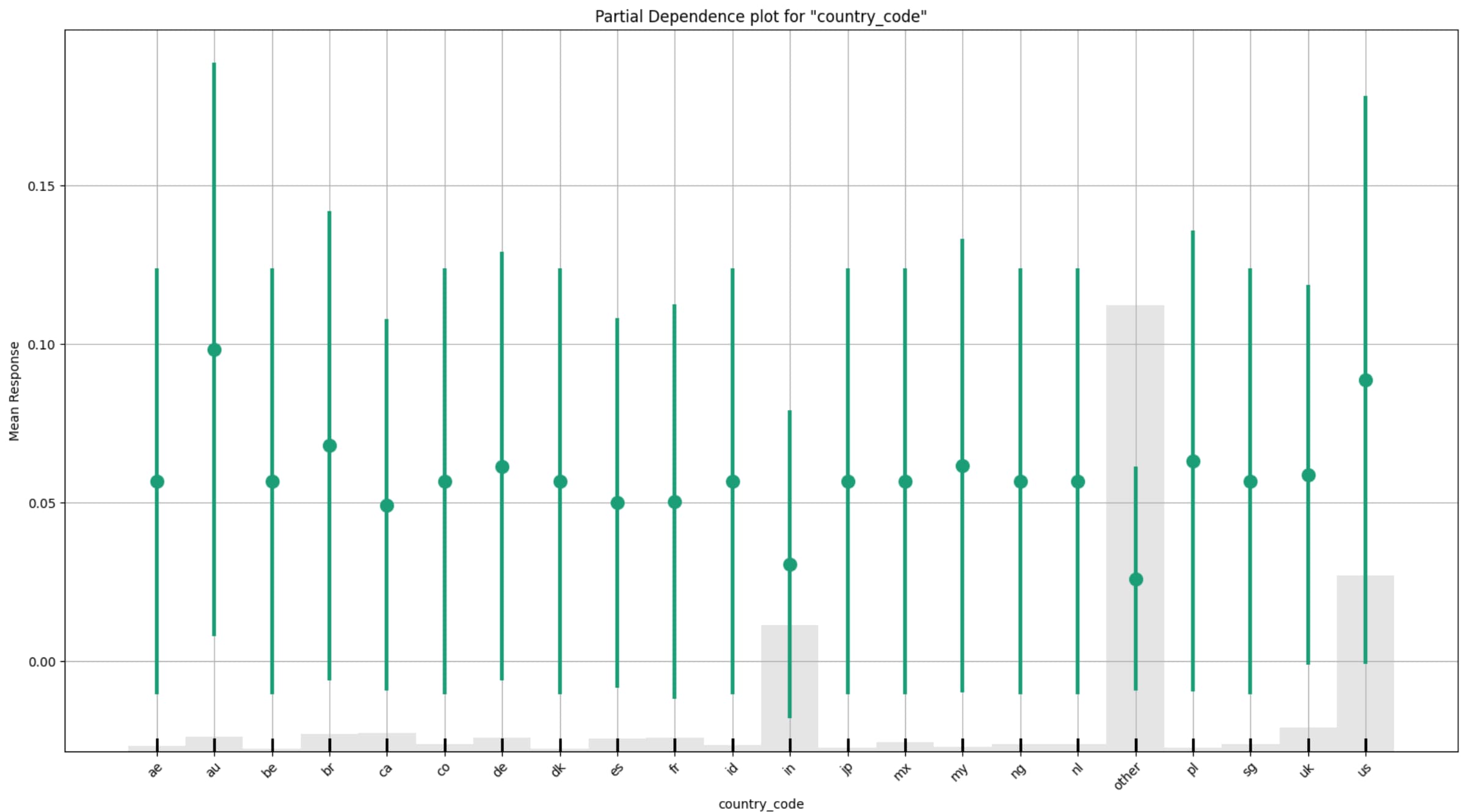
從上圖可以看到,類別型特徵 country_code,在不變動其他特徵下,圖中每個類別的綠點,表示模型預測的平均購買機率(Mean Response)。綠點較高,表示該國家傾向更高的購買機率。
預測結果
利用最佳模型對所有潛在用戶進行預測,並將預測結果predictions_df存回原資料庫leads_df中。
1 | predictions_df = best_model_h2o.predict(hf).as_data_frame() |
1 | # 建立資料庫連線 |
讀取預測結果:
1 | # 讀取資料表(例如:leads_ltb_h2o) |
| mailchimp_id | user_full_name | user_email | member_rating | optin_time | country_code | made_purchase | optin_days | email_provider | predict | p0 | p1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | Garrick Langworth | garrick.langworth@gmail.com | 2 | 2019-05-22 00:00:00.000000 | in | 1 | -589 | gmail.com | 0 | 0.961327 | 0.038673 |
| 4 | Cordell Dickens | cordell.dickens@gmail.com | 4 | 2018-11-19 00:00:00.000000 | other | 1 | -773 | gmail.com | 0 | 0.927102 | 0.072898 |
predict: 模型預測該潛在用戶是否會購買。0: 表示預測這個用戶「不會購買」產品。1: 表示預測這個用戶「會購買」產品。
p0: 用戶「不會購買」的機率。p1: 用戶「會購買」的機率。
行銷跟進策略
| 評分等級 | p1範圍 | 行銷策略方向 | 跟進策略方案 | 預算分配 |
|---|---|---|---|---|
| Hot🔥 | ≥0.8 | 立即轉換 | -提供限時獨享優惠或專屬折扣,如專屬優惠VIP折扣碼,限時72小時有效的折扣碼。 -提供一對一線上免費諮詢或體驗試用。 -個性化電子郵件、LINE推播或專人電話聯繫。 |
50% |
| Warm🌤 | 0.6-0.8 | 價值建立 | -提供教育性內容,如使用攻略、成功案例分享影片,來強化產品信任感。 -透過輕鬆互動,如抽獎、問答活動,增加參與感及興趣。 -寄送產品使用體驗調查或試用小包裝,鼓勵提升興趣。 |
30% |
| Cold❄️ | 0.4-0.6 | 興趣喚醒 | -提供基礎知識型內容,如新手教學、產品Q&A等,建立認知。 -使用趣味性遊戲或輕量互動式小測驗,增加潛在興趣。 -透過再行銷廣告反覆曝光,以加深印象。 |
15% |
| Non-Target🚫 | <0.4 | 低成本跟進 | -減少主動行銷資源,僅以自動化電子報定期聯絡。 -提供廣泛且普遍的內容,如部落格文章、常見問題集等,低成本維持品牌接觸點。 |
5% |
總結
本專案運用 H2O AutoML 自動化建立預測模型的完整流程,並結合行銷策略分級,根據預測結果提供不同等級用戶的跟進策略,而能專注於高潛力用戶,提升行銷資源的運用效率。
未來模型還可改進方向:
- 類別不平衡處理
- 增強特徵工程
- 模型訓練的超參數調優
希望本篇文章對你實作 H2O AutoML 的應用有所幫助!期待在下方留言區看到你的見解或問題喔~