上一篇我們完成 Oracle Database 23ai Free 的開發環境,如果還沒設定好的話,請看 Win 安裝 Oracle VM VirtualBox + Database 23ai。
本篇會先帶大家了解向量搜尋基本概念後,再分享如何使用 Oracle 資料庫和 LangChain 建立一個 RAG 應用,是參照 Oracle LiveLabs 這篇 AI Vector Search - 7 Easy Steps to Building a RAG Application using LangChain 的教學來實現「使用 Oracle 向量資料庫和 LangChain 開發 RAG 應用」。
什麼是向量
向量(Vector)在數學和物理學中通常表示為一個有序的數值集合,能夠同時描述大小和方向。當我們將資料表示為向量時,每個向量都對應於高維空間中的一個點。
透過向量之間的距離,我們可以發現不同資料點之間的相似性或關聯性。舉個例子,如果我們將「蘋果」、「香蕉」和「貓」這些詞語嵌入到一個高維空間中,我們可能會發現「蘋果」和「香蕉」的向量會靠近,因為它們都是水果,有著相似的語義特徵,而「貓」則屬於完全不同的類別。
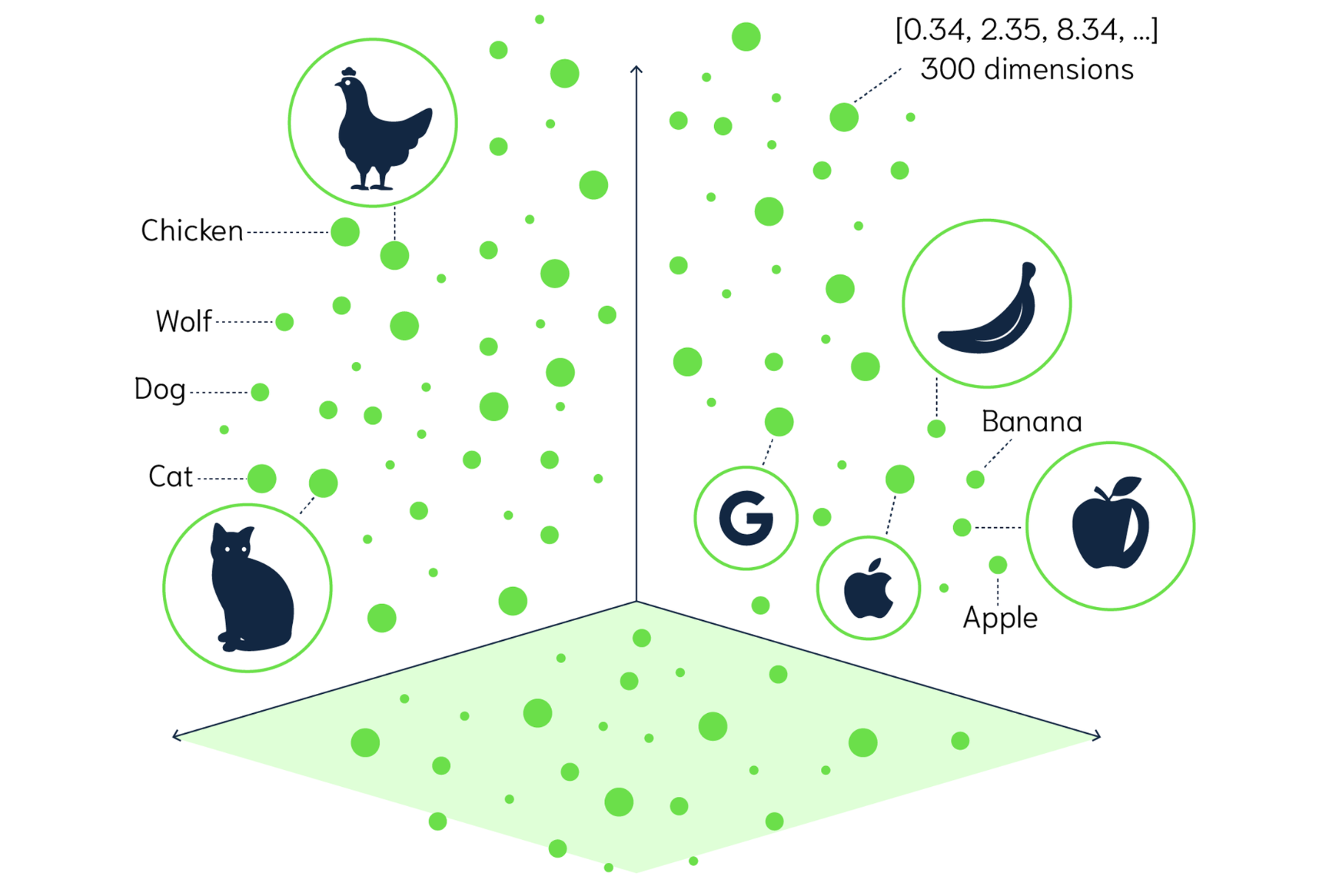
在資料科學中,向量通常是用來表示一個樣本的多個特徵的組合。
比如,以鳶尾花資料集為例子:
- 有 3 種種類
- 每種類有 50 個樣本,總共 150 個樣本
- 每個樣本有 4 個特徵
- 花萼長度(sepal length), 花萼寬度(sepal width), 花瓣長度(petal length), 花瓣寬度(petal width)
- 每個樣本的特徵可以表示為一個 4 維向量,例如:$\vec{v} = [\text{sepal_length}, \text{sepal_width}, \text{petal_length}, \text{petal_width}] = [5.1, 3.5, 1.4, 0.2]$
- 每個樣本對應到特徵空間中的一個點,這個點的位置由這 4 個特徵值決定。
- 因此,整個資料集的形狀是 (150, 4),這表示有 150 個樣本,每個樣本包含 4 個特徵。在特徵空間中,這 150 個樣本就對應到 150 個不同的點,每個點的位置由該樣本的 4 個特徵值決定。
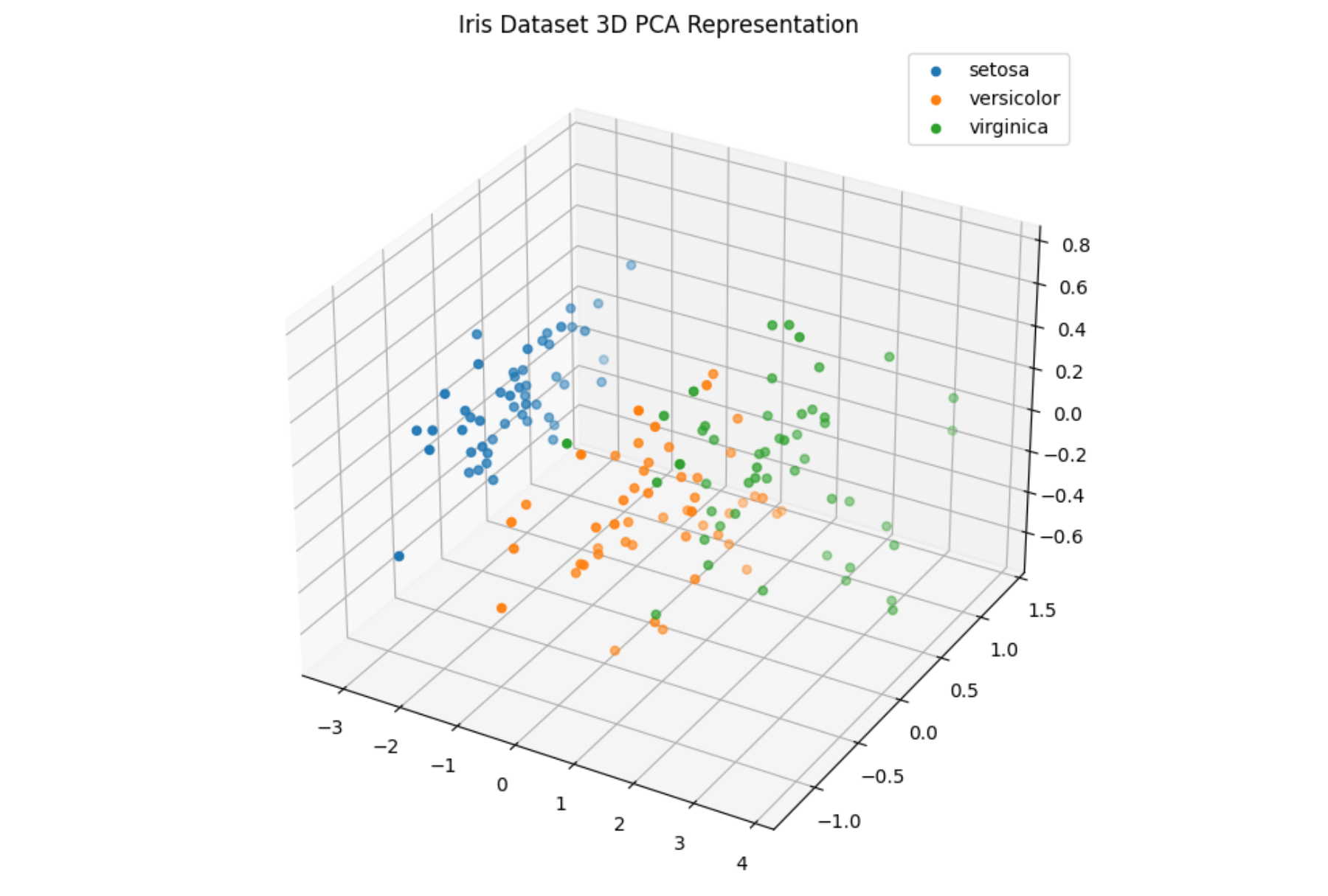
向量(Vector)是一個數值集合,用來描述資料點的大小和方向。在資料科學中,我們可以用向量來表示樣本的多個特徵,透過計算向量之間的距離來評估它們的相似性。
什麼是向量搜尋
向量搜尋(Vector Search)是一種利用向量來進行相似度檢索的技術。
- 向量搜索是達成語意(Semantic)搜尋的關鍵技術。
- 通常用於文本、圖像、音訊、影片等非結構性資料。
- 核心概念是將資料轉換為多維空間中的向量,然後比較向量的距離來評估向量相似度。
資料轉向量
資料轉換為向量的過程稱為「特徵向量化」(Embedding),而不同的資料類型(如文本、圖像、音訊、影片等)需要不同的技術來實現這個轉換。
文本
MiniLM-L6-v2 多語言模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
texts = [
"請到Github追蹤我",
"我的文章產出更快😎"
]
embeddings = model.encode(texts)
print(f"向量形狀: {embeddings.shape}")
for i, text in enumerate(texts):
print(f"文本: {text}")
print(f"向量: {embeddings[i][:3]} ... {embeddings[i][-3:]}\n")
|
1
2
3
4
5
6
| 向量形狀: (2, 384)
文本: 請到Github追蹤我
向量: [-0.21761326 -0.22119161 0.12100245] ... [-0.02576047 -0.1395366 -0.22299667]
文本: 我的文章產出更快😎
向量: [ 0.0126495 -0.17077899 -0.15991284] ... [ 0.03999303 0.06574974 -0.02783584]
|
MiniLM-L6-v2 英文模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
texts = [
"Follow me on GitHub!",
"My content is coming out faster😎"
]
embeddings = model.encode(texts)
print(f"向量形狀: {embeddings.shape}")
for i, text in enumerate(texts):
print(f"文本: {text}")
print(f"向量: {embeddings[i][:3]} ... {embeddings[i][-3:]}\n")
|
1
2
3
4
5
6
| 向量形狀: (2, 384)
文本: Follow me on GitHub!
向量: [-0.04050694 -0.08719105 -0.03941791] ... [-0.06001 0.01527704 -0.01108771]
文本: My content is coming out faster😎
向量: [ 0.0213392 -0.064215 0.04405481] ... [-0.00864242 -0.00494845 -0.06258776]
|
圖像
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
import torch
import torchvision.transforms as transforms
from PIL import Image
import requests
from io import BytesIO
model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True)
model = torch.nn.Sequential(*(list(model.children())[:-1]))
model.eval()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
def embed(image):
image = transform(image).unsqueeze(0)
image = image.to(device)
with torch.no_grad():
output = model(image).squeeze()
return output.cpu().numpy()
url = "https://storage.googleapis.com/kagglesdsdata/datasets/42780/75676/natural_images/airplane/airplane_0000.jpg?X-Goog-Algorithm=GOOG4-RSA-SHA256&X-Goog-Credential=gcp-kaggle-com%40kaggle-161607.iam.gserviceaccount.com%2F20241006%2Fauto%2Fstorage%2Fgoog4_request&X-Goog-Date=20241006T073449Z&X-Goog-Expires=259200&X-Goog-SignedHeaders=host&X-Goog-Signature=4ebaca968963cb88271c1f13f037654c8f7318b590e079a1f0ecaf60c710297fb1bc18dc3a6ae00fbdfcaf00ff10f5e7d358d5be21c572bb6f5eabe8aa64f62b11f6b4d7e360037f56c3cfb270e478d299b1cf875e794360d7a2041bb982f693d8a799c6a687efc16dc9b78e5f826ace5e5e5498fca8edc6644306b94546bea7140f59c839bd6e27833b82e9ffea3448e0ed98e14a6e78762c5eaee7fc51e9076f78e0976e029590b23e22051ae8ac4ff211a3f4644e1c47092a2fc5bdeb1d27230bf27b9f83e244b72dc95d0d1b40aa88012f6c37f68d2b8c96e916c0e35355ed9352650664faa08ff4996ead8faf9d3a634781f2783ec3b472f37222089fd3"
response = requests.get(url)
img = Image.open(BytesIO(response.content))
embedding = embed(img)
print("向量形狀:", embedding.shape)
print("向量:", embedding)
|
1
2
| 向量形狀: (2048,)
向量: [0.2375403 0.46847472 0.49034768 ... 0.20775649 0.33074814 0.27442572]
|
計算向量距離
向量搜尋的關鍵是如何衡量兩個向量之間的相似度。
以下是常見的幾種相似度度量方法:
內積
內積(Dot Product)衡量兩個向量之間的點積。
$$A \cdot B = \sum_{i=1}^{n} A_i B_i$$
1
2
3
4
5
6
7
8
9
| import numpy as np
A = np.array([1, 2, 3])
B = np.array([4, 5, 6])
dot_product = np.dot(A, B)
print(f"內積: {dot_product}") # 內積: 32
|
歐氏距離
歐氏距離(Euclidean Distance)衡量兩個向量之間的直線距離。
$$d(x, y) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2}$$
1
2
3
4
5
6
7
8
9
| import numpy as np
x = np.array([1, 2, 3])
y = np.array([4, 5, 6])
euclidean_distance = np.linalg.norm(x - y)
print(f"歐氏距離: {euclidean_distance}") # 歐氏距離: 5.196152422706632
|
餘弦相似度
餘弦相似度(Cosine Similarity)衡量兩個向量之間的夾角餘弦值,而不考慮向量的大小。
$$\text{Cosine Similarity}(a, b) = \frac{\vec{a} \cdot \vec{b}}{||\vec{a}|| \cdot ||\vec{b}||}$$
1
2
3
4
5
6
7
8
9
| import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
cosine_similarity = np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
print(f"餘弦相似度: {cosine_similarity}") # 餘弦相似度: 0.9746318461970762
|
曼哈頓距離
曼哈頓距離(Manhattan Distance)衡量兩個向量在每個維度上的絕對差值之和。
$$d(x, y) = \sum_{i=1}^{n} |x_i - y_i|$$
1
2
3
4
5
6
7
8
9
| import numpy as np
# 定義兩個向量
x = np.array([1, 2, 3])
y = np.array([4, 5, 6])
# 計算曼哈頓距離
manhattan_distance = np.sum(np.abs(x - y))
print(f"曼哈頓距離: {manhattan_distance}") # 曼哈頓距離: 9
|
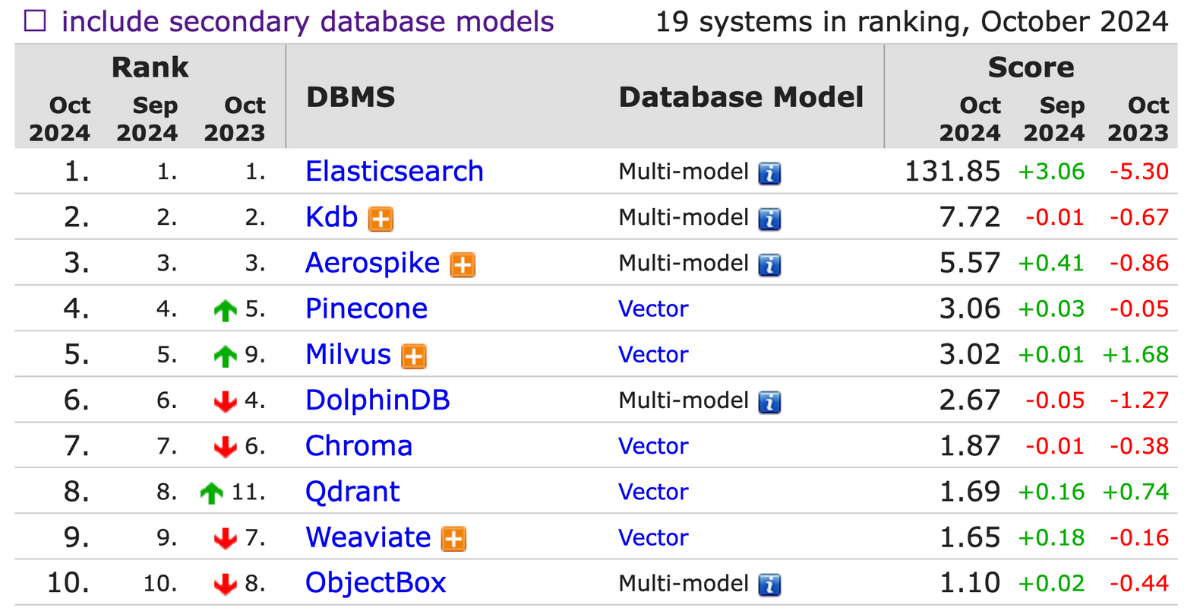
向量資料庫排名
是不是會好奇那目前向量資料庫排名呢?可以參考以下的向量資料庫排名,DB-Engines Ranking 是根據資料庫管理系統的受歡迎程度對向量資料庫進行排名,排名每個月更新一次。
什麼是 RAG
RAG(Retrieval Augmented Generation, 檢索增強生成),是一種結合語言模型和向量資料庫的應用。利用「語言模型的生成能力」和「向量資料庫的檢索能力」來提高生成回應的相關性和準確性。
RAG 的主要原理是:當使用者提出問題時,系統首先從向量資料庫中檢索出與問題相關的資料,然後基於這些檢索結果,語言模型再進行答案生成。
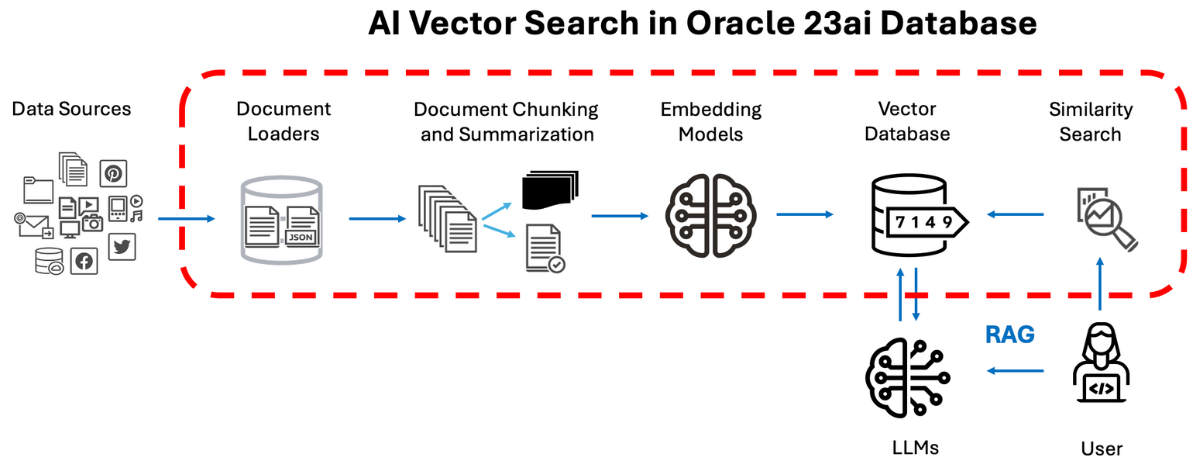
RAG 是結合「語言模型」和「向量資料庫」,使用者用自然語言進行互動問答,結果會比僅依靠「語言模型」更精準且能即時更新資料,簡單來說,RAG 就像是一個特定領域的 AI 專家。
如果想更了解 RAG,這篇文章寫得非常好,可以參考 RAG 解決方案規劃與實作。
實作流程
這次專案是實作「使用 Oracle 向量資料庫的 RAG 應用」,主要會處理一份 PDF 文件,提取文本、向量化後,再存入 Oracle 資料庫中,讓使用者能夠用問答方式查詢 PDF 的資訊。PDF 文件是使用 202402_2330_AI1_20241003_160741.pdf,這是台積電的 2024 Q2 財報,你可以使用其他文件,或是也可以用這份文件來測試 RAG 的功能。
主要功能:
- PDF 處理:將 PDF 文件轉換為文本區塊。
- 向量化:使用 HuggingFace 的嵌入模型將文本轉換為向量。
- 整合 Oracle 資料庫:將向量化的文檔存入並從 Oracle 資料庫向量檢索。
- 問答功能:根據文檔內容及 gpt-4 生成用戶查詢的答案。
完整程式碼
總結
在資料科學中,向量通常是用來表示樣本的多個特徵的組合。利用這些向量,我們能更有效地處理非結構化數據,如文本、圖像和音訊等,並且進一步進行語意分析、相似度檢索、建模與預測等。
實作介紹如何使用 Oracle 向量資料庫結合 LangChain 構建 RAG 應用,打造出語意搜尋問答機器人。這種 RAG 技術能夠結合「生成」與「檢索」,顯著提高生成回應的準確性,從而應用在文件分類、搜尋最相近內容、智能客服、知識庫管理和企業資訊查詢等場景。